
Recursion
목표
- 재귀 문제를 recursive step과 base case로 분리할 수 있다.
- recursion에서 help메서드를 사용하는 시기와 방법을 알 수 있다.
- recursion과 iteration의 장점과 단점을 이해 할 수 있다.
Recursion
우리는 이미 spec이 있는 경우 메소드를 구현하는 방법에 대해서 알아 볼 것이다.
→ recursion은 모든 문제에 유용한 것은 아니지만 소프트웨어 개발을 하는데에 있어서 많은 사람들이 고민을 한다.
Recursion function은 base case와 recursive step로 구분된다.
- base case : 함수 호출에 대한 입력이 주어지면 바로 결과를 계산한다.
- recursive step : 동일한 함수에 대한 하나 이상의 recursive function을 사용해서 결과를 계산하지만 입력의 크기나 복잡성은 감소하여 base case에 가까워진다.
factorial을 계산하는 함수를 고려할 때 두가지 방법을 사용 할 수 있다.
Product
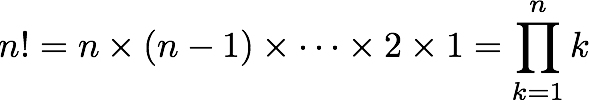
Recurrence relation(회귀 관계)
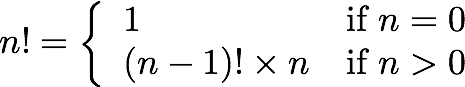
이 두가지 방식은 다른 구현으로 이어진다.
Iterative
public static long factorial(int n) {
long fact = 1;
for (int i = 1; i <= n; i++) {
fact = fact * i;
}
return fact;
}Recursive
public static long factorial(int n) {
if (n == 0) {
return 1;
} else {
return n * factorial(n-1);
}
}**base case : n = 0이다. 여기서 계산하고 즉시 결과를 반환한다. 0! = 1로 정의됨**
**recursive step : (n-1)을 얻기 위해 재귀 호출을 통해 결과를 계산한다. n을 곱하여 계산을 완료한다.**
****재귀 함수 호출을 시각화 하려면 현재 실행중인 함수의 호출 스택을 다이어그램으로 작성하는 것이 도움된다.****
**factorial 기본 메소드에서 재귀 구현**
public static void main(String[] args) {
long x = factorial(3);
}다이어그램으로 그린 호출 스택

- 다이어그램에서 우리는
factorial이 0을 호출 할 때 까지 메인이 팩토리얼을 호출하고 팩토리얼이 스스로를 어떻게 호출하는지를 볼 수 있다. - 0을 만나면
factorial(3)이 메인으로 반환 될 때 까지 각 호출은 호출자에게 결과값을 반환한다.
위 사진은 factorial의 interactive visualization(대화형 시각화)이다. 계산을 단계별로 진행하고 어떤 방식으로 Recurision이 이루어지는지 알 수 있다. 스택 프레임이 위로 자라는 대신 아래로 늘어난다.
또 다른 예시인 Fibonacci
/**
* @param n >= 0
* @return the nth Fibonacci number
*/
public static int fibonacci(int n) {
if (n == 0 || n == 1) {
return 1; // base cases
} else {
return fibonacci(n-1) + fibonacci(n-2); // recursive step
}
}→ 피보나치 함수는 base case가 n = 0, n = 1로 두가지가 있다.
- 최대 깊이까지 꾸준히 증가한 뒤 답으로 축소되는 팩토리얼과는 다르게 피보나치의 스택은 계산 과정에서 반복적으로 증가하고 축소한다.
Choosing the Right Decomposition for a Problem
메소드 구현과 같이 문제를 분해하는 올바른 방법을 찾는 것은 중요하다.
좋은 분해는 간단하고, 짧고, ETU, SFB, RFC를 가지고 있다.
재귀에 적합한 스펙 구현 예시
/**
* @param word consisting only of letters A-Z or a-z
* @return all subsequences of word, separated by commas,
* where a subsequence is a string of letters found in word
* in the same order that they appear in word.
*/
public static String subsequences(String word)ex) subsequences("abc") → “abc,ab,bc,ac,a,b,c,”
(문장 뒤에 오는 , 또한 유효함)
해당 문자를 포함하는 한 세트의 substring과 해당 문자를 제외하는 다른 substring 구성할 수 있으며, 두 세트는 가능한 세트를 포함한다.
public static String subsequences(String word) {
if (word.isEmpty()) {
return ""; // base case
} else {
char firstLetter = word.charAt(0);
String restOfWord = word.substring(1);
String subsequencesOfRest = subsequences(restOfWord);
String result = "";
for (String subsequence : subsequencesOfRest.split(",", -1)) {
result += "," + subsequence;
result += "," + firstLetter + subsequence;
}
result = result.substring(1); // remove extra leading comma
return result;
}
}Structure of Recursive Implementations
Recursive implementation은 항상 두가지 부분으로 나뉜다.
- base case : 문제에서 가장 단순하고 작은 부분으로 더 분해 할 수 없다. base case는 비어있는 경우를 포함하는 경우가 종종 있다.(empty String, empty list, empty set, empty tree , zero, etc)
- Recursive step : 문제의 더 큰 인스턴스를 재귀 호출로 해결할 수 있는 하나 이상의 더 간단하거나 작은 인스턴스로 분해한 뒤 그 결과를 재결합하여 원래 문제에 대한 결과를 만든다.
**Recursive step 에서는 문제 인스턴스를 더 작게 분할 하는 것이 중요하다. 그렇지 않으면 재귀가 끝나지 않을 수 있다. 모든 recursive step이 문제를 분할하고 base case가 맨 아래에 있다면 Recursion는 유한하다는 것을 보장한다.**
Recursion에는 Base case 혹은 Recursive step가 2개 이상 있을 수 있다.
ex) 피보나치 함수에는 n = 0과 n = 1이라는 두가지 base case가 있음
Helper Methods
위 subsequences() 코드는 문제에 가능한 재귀 분해 중 하나이다.
- 하위 문제(첫 번째 문자를 제거한 후 문자열의 나머지 하위 시퀀스)에 대한 솔루션을 선택하고 이를 사용해서 각 하위 시퀀스를 가져온 뒤 첫 번째 문자를 추가하거나 생략함으로써 원래 문제에 대한 결과값을 제공했다.
→ 기존 스펙을 사용하여 하위 문제를 해결하는 직접적인 재귀 구현이다.
재귀 문제를 더 간단하고 예쁘게 만들기 위해서 재귀 단계에 대해 더 강력한 스펙을 요구하는 것이 유용할 수 있다.
ex) “orange”
partial : “o” word : “range”
/**
* Return all subsequences of word (as defined above) separated by commas,
* with partialSubsequence prepended to each one.
*/
private static String subsequencesAfter(String partialSubsequence, String word) {
if (word.isEmpty()) {
// base case
return partialSubsequence;
} else {
// recursive step
return subsequencesAfter(partialSubsequence, word.substring(1))
+ ","
+ subsequencesAfter(partialSubsequence + word.charAt(0), word.substring(1));
}
}이러한 메서드를 Helper Method 라고 한다.
- 새로운 파라미터를 가지고 있기때문에 원본과 다른 Spec을 만족시킨다.
- 이 매개변수는
iterative implementation과 유사한 역할을 한다. (계산이 진행되는 동안 임시 상태를 유지한다.) - 재귀 호출은 단어의 각 문자를 선택하거나 무시하면서 하위 시퀀스를 꾸준히 확장하여 마침내 단어 끝에 도달할 때 까지(base case)까지 하위 시퀀스가 반환된다. 그 후 가능한 부분 하위 시퀀스를 역추적한다.
구현을 완성하기 위해서 subsequences 파라미터 값을 사용하여 helper method 을 호출하여 기존 subsequence 를 완성해야한다.
public static String subsequences(String word) {
return subsequencesAfter("", word);
}클라이언트에게 helper method 를 호출해서는 안된다.
**partialSubsequence 재귀에서 같이 임시 변수가 필요하다는 사실을 발견 했을 때 메서드의 기존 스펙을 변경하지 말고 클라이언트가 매개변수를 변경하도록 강요하지라.**
→ 구현이 클라이언트에 노출되고 나중에 이를 변경 할 수 있는 능력이 줄어듬
→ 재귀에 helper method 를 사용하고 위에 표시한 대로 공용 메서드에서 올바른 초기화를 사용하여 이를 호출하도록한다.
Helper method
- 클라이언트가 호출 할 수 없도록
private - 재귀에서 사용한다.
- 새로운 파라미터를 가지고 있음(계산 하는 동안 상태를 임시로 가짐)
Choosing the Right Recursive Subproblem
또 다른 예시로 이런 스펙에 따라 주어진 base case를 사용하여 문자열 표현으로 변환한다고 가정한다.
/**
* @param n integer to convert to string
* @param base base for the representation. Requires 2<=base<=10.
* @return n represented as a string of digits in the specified base, with
* a minus sign if n<0.
*/
public static String stringValue(int n, int base)ex)
stringValue(16,10) → return "16"
**stringValue(16,2) → return “10000”**
재귀적으로 구현을 한다고 할 때 recursive step는 간단하다.
해당 양의 정수 표현을 재귀적으로 호출하여 간단히 음의 정수를 처리 할 수 있다.
if (n < 0) return "-" + stringValue(-n, base);이는 recursive subproblem이 매개변수의 값이나 문자열 또는 List의 크기보다 더 미묘한 방식으로 작거나 단순 할 수 있음을 보여준다. → 문제를 양의 정수로 줄임으로써 효과적으로 줄였다.
다음 질문은 양수 n(ex: 10진수에서 n = 829)인 경우 이를 어떻게 recursive subproblem으로 분해해야하는가이다. 종이에 적을 때 숫자를 생각하면 8(가장 왼쪽, 가장 높은 숫자) 또는 9(가장 오른쪽, 낮은 순서의 숫자)로 시작할 수 있다.
→ 왼쪽 끝에서 시작하는 것이 자연스럽다.(우리가 쓰는 방향이니까)
가장 왼쪽 숫자를 추출하는 방법을 알아내기 위해서 먼저 숫자의 자릿수를 찾아야한다.
대신, n을 분해하는 좋은 방법으로는 나머지 값으로 밑수를 취하고 밑수로 나누는 것이다.
return stringValue(n/base, base) + "0123456789".charAt(n%base);
// Q1. 이건 recursive step다.
// -> base case를 작성해야할까? 한다면 어떻게 작성해야할까?→ 문제를 분해하는 여러가지 방법을 생각하고 recursive step를 작성해보아라.
가장 간단하고 자연스러운 recursive step를 생성하는 단계를 찾고 싶다.
base case가 무엇인지 파악하고 recursive step와 base case를 구별하는 if문을 포함하는 작업이 남아있다.
Recursive Problems vs. Recursive Data
지금까지 우리가 본 예시들은 문제 구조가 재귀적 정의에 적합한 경우였다.
Factorial은 더 하위문제로 정의하기 쉽다. 이와 같이 재귀적 문제가 발생하면 재귀적으로 해결해야한다는 신호 중 하나다.
또 다른 단서로는 작업 중인 데이터가 구조상 재귀적일 때이다. 지금부터 재귀 데이터의 예시를 볼 것이다.
Java 라이브러리는 java.io.File 를 사용하여 파일 시스템을 나타낸다.
이는 f.getParentFile()이 File 객체인 f의 상위 폴더를 반환하고 f.fileFiles() 가 f가 포함된 파일들을 반환한다는 것이 recursive type이다.
Recursive Data의 경우 재귀적으로 구현하는 것이 당연함.
/**
* @param f a file in the filesystem
* @return the full pathname of f from the root of the filesystem
*/
public static String fullPathname(File f) {
if (f.getParentFile() == null) {
// base case: f is at the root of the filesystem
return f.getName();
} else {
// recursive step
return fullPathname(f.getParentFile()) + "/" + f.getName();
}
}최신 버전 Java에는 파일 시스템과 파일 이름을 지정하는 데 사용되는 경로 이름을 더욱 명확하게 구분하는 새로운 API인 java.nio.Files , java.nio.Path 를 추가했다. 그러나 데이터 구조는 여전히 기본적으로 재귀적이다.
Reentrant Code(재진입 코드)
자신을 호출하는 메소드인 재귀는 reentrancy 라고 불리는 프로그래밍의 일반적인 현상의 특별한 경우이다. reentrancy code는 안전하게 다시 입력될 수 있다. → 즉, 호출이 진행되는 동안에도 다시 호출될 수 있다.
**reentrant code(재진입 코드) 는 파라미터와 지역 변수에서 상태를 완전히 유지하고, 전역이나 정적 변수를 사용하지 않으며 프로그램의 다른 부분이나 자신에 대한 다른 호출과 mutable object에 대한 alias를 제공하지 않는다.**
직접 재귀는 재진입이 발생할 수 있는 한가지 방법이다. factorial() 메소드는 factorial(n) 이 완료되지 않더라도 factorial(n - 1) 을 호출 할 수 있도록 설계 되었다.
둘 이상의 함수 간의 상호 recursive reentrant이 발생할 수 있는 또 다른 방법이다.
ex) A가 B를 호출하고 B가 다시 A를 호출한다.
이러한 코드는 항상 프로그래머가 의도하고 설계된 것이어야 한다. 예상치 못한 상호 재귀로 인해서 버그가 발생할 수 있다.
가능한 Reentrant 이 가능하도록 코드를 설계하는 것이 좋다. Reentrant Code 는 버그로부터 안전하고 동시성, 콜백또는 상호 재귀와 같은 더 많은 상황에서 사용할 수 있다
When to Use Recursion Rather Than Iteration
재귀를 사용하는 두 가지 일반적인 이유를 살펴보았다.
- 문제는 자연스럽게 재귀적이다.(피보나치)
- 데이터는 자연스럽게 재귀적이다.(파일시스템)
재귀를 사용하는 또 다른 이유는 불변성을 더 많이 활용하기 위해서이다. 이상적인 재귀에는 모든 변수가 final 이고 재귀 메서드는 아무것도 변경하지 않는다는 점에서 모두 pure한 순수함수 이다. (상태가 없음)
메소드의 동작은 프로그램의 다른 부분에 side-effect가 없는 매개 변수와 반환 값 간의 관계로 간단히 이해될 수 있다. 이러한 종류의 패러다임을 functional programming(함수형 프로그래밍)이라고 하며, 루프와 변수를 사용한 명령형 프로그래밍보다 추론하기 훨씬 쉽다.
이와 반대로 iteration 구현에서는 반복 과정에서 수정되는 변수가 final이 아닌 mutable object가 필연적으로 발생한다. 순수한 입력/출력에 대해서 생각하는것이 아닌 다양한 시점의 프로그램의 상태 스냅샷에 대해서 생각해야한다.
→ Q2. iteration보다 recursion이 좋은 이유?
장점: iteration은 Mutable object가 무조건적으로 발생할 수 있지만 Recursion은 side-effect가 없이 구성 할 수 있기 때문에 반환 값등을 유추하기가 쉬움
단점:
재귀의 한 가지 단점은 iteration보다 더 많은 메모리를 사용할 수 있다. 재귀 호출 스택을 구축하면 일시적으로 메모리가 소비되고 스택 크기가 제한되어 재귀 구현으로 해결할 수 있는 문제의 크기가 제한 될 수 있다.
Common Mistakes in Recursive Implementations
재귀에서 잘못 구현될 수 있는 두가지 경우
- base case 가 완전히 누락되었거나 문제 두 개 이상의 base case가 필요하지만 모든 경우를 적지 않았을 때
- recursive step가 하위 문제로 축소되지(분할되지) 않으므로 재귀가 되지 않는 경우
디버깅 할 때 이를 생각해보아라.
긍정적으로는 반복 구현 부분에서 무한 루프가 발생하면 StackOverflowError 이 발생한다.
버그가 있는 재귀는 더 빨리 실패한다.
Summary
우리는 다음과 같은 아이디어를 다뤘다.
- recursive problems and recursive data
- 재귀 문제의 대체 분해 비교
- recursive step를 강화하기 위해서 helper method 사용
- recursion vs. iteration
- SFB : 재귀 코드는 더 간단하며 immutable variables과 immutable object를 사용한다.
- ETU : 반복으로 푸는 방법과 반복적인 데이터에 등에 대한 반복적인 구현보다 짧고 이해하기 쉽다.
- RFC : 재귀 코드는 자연스럽게
Reentrant(재진입)이 가능하므로 버그로부터 안전하고 더 많은 상황에서 사용할 수 있다.
'Java > MIT' 카테고리의 다른 글
| Reading 8: Avoiding Debugging (0) | 2023.10.23 |
|---|---|
| Reading 7: Designing Specifications (0) | 2023.10.17 |
| Reading 6: Specifications - MIT 6.005 (0) | 2023.09.24 |
| Reading 5: Version Control - MIT 6.005 (0) | 2023.09.18 |
| Reading 4: Code Review - MIT 6.005 (0) | 2023.09.17 |